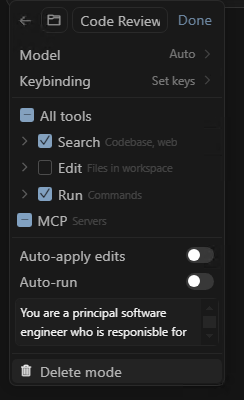
Do you have a bank of prompts you copy/paste into the Cursor chat when you want to achieve a specific task? Maybe it's when you want to do a code review, maybe it's when you want it to write unit tests for some new code, maybe it's when you what it to add OpenAPI specification... Continue Reading →
Streamline development tasks using personalised Custom Modes in Cursor