While Azure Front Door promises to provide resilience and automatic failure over to alternate backends, I’ve found it a bit tricky to determine how to eliminate downtime when doing blue/green deployments, or if you want to take a specific backend service offline to perform upgrades or maintenance.
It appears I’m not the only one:
load balancing – Azure Front Door – How to do rolling update of backend pool? – Stack Overflow
Azure Front Door – Backend host update delay – Microsoft Q&A
Let’s take a look at a very simple configuration of an Azure Function App (CamtosoServiceA) with a Front Door sitting in front of it. All traffic arriving at the Front Door (camtososervice.azurefd.net) is routed through the the backend Function App (camtososervicea.azurewebsites.net).

The Function App I’m using in this article is incredibly simple. It just responds to a GET request with the BuildName (which is an App Setting) and a timestamp. I’m going to use this BuildName App Setting so that we can create two instances of the Function App and configure one with BuildName “A” and another with build name “B” to illustrate blue/green deployments and tell which backend is responding to our calls. Here’s the code from the function app.
public static class TestHttpTrigger
{
[FunctionName("knock-knock-whos-there")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
return new OkObjectResult($"BuildName: {Environment.GetEnvironmentVariable("BuildName")}, Timestamp: {DateTime.UtcNow.ToLongTimeString()}");
}
}
If we make a call via the Front Door domain, CamtosoServiceA responds as expected (which we can tell because it is responding with ‘BuildName: A’).

With this initial Front Door configuration, you could imagine that doing a scripted (via Azure DevOps Pipeline) development of your latest build under a blue/green deployment model would be fairly straight forward.
- Step 1 – provision new build of the service CamtosoServiceB
- Step 2 – add CamtosoServiceB to Front Door
- Step 3 – remove CamtosoServiceA from Front Door
- Step 4 – decommission CamtosoServiceA
So lets manually walk through those steps and watch what happens.
Step 1 – Provision new build of the service CamtosoServiceB
We have built a new improved build of the service (build B) and under a blue/green deployment model we have provisioned a the new function app CamtosoServiceB and it has its own unique URL which we can test directly to confirm it is working. Notice is responds with ‘BuildName: B’.

Step 2 – Add CamtosoServiceB to Front Door
Now we add CamtosoServiceB to Front Door and leave CamtosoServiceA as well for the moment, this should give us the overlap to avoid any downtime in our service.
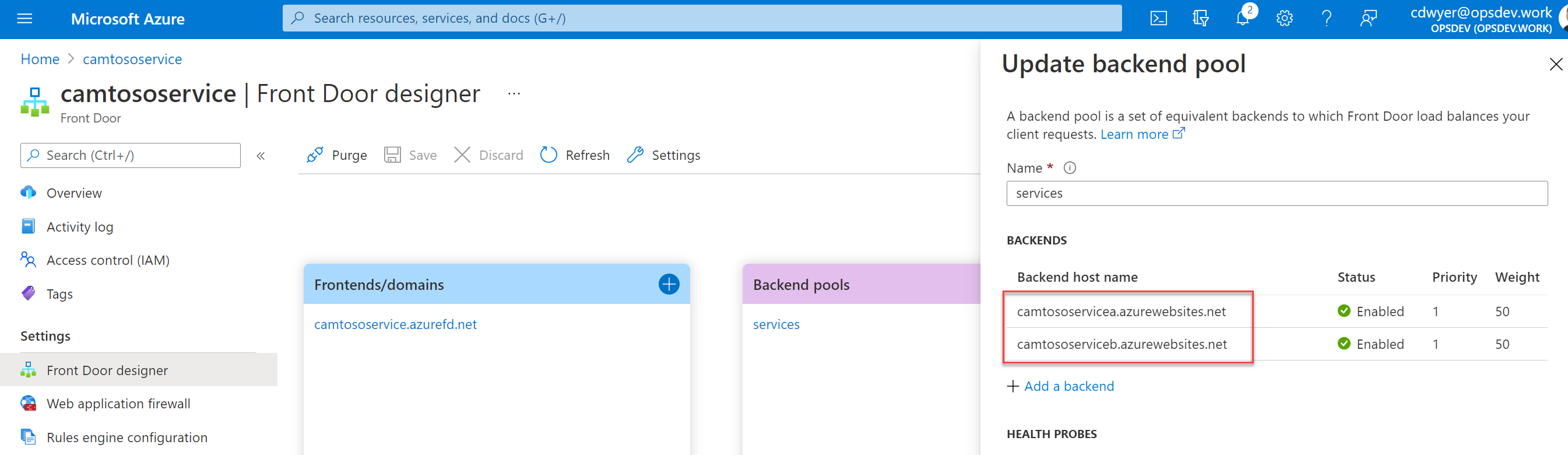
Running a test against the Front Door domain you can see ServiceA is responding but it would be fair to assume that either ServiceA or ServiceB could respond at this stage since we have a health probe being sent from Front Door every 30 seconds and from the Front Door config it looks like both backends are healthy and active (as you’ll see in a second this is a very dangerous and false assumption)

So lets move onto the next step
Step 3 – Remove CamtosoServiceA from Front Door
Now we remove ServiceA from Front Door leaving ServiceB as the only remaining backend.
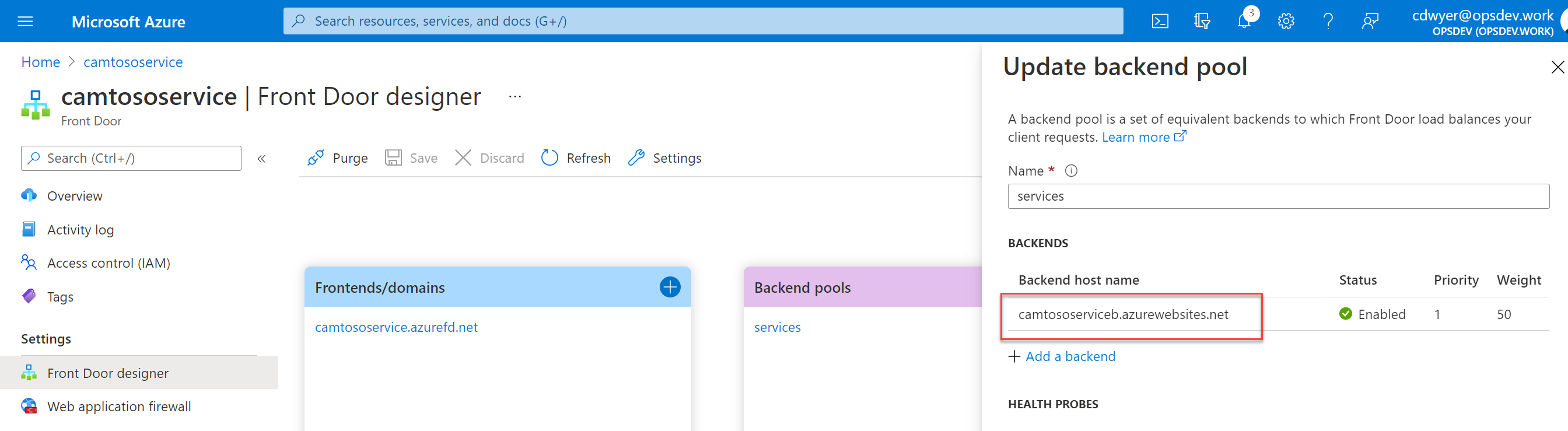
After removing ServiceA, lets hit the Front Door domain again to make sure ServiceB is responding. What, ServiceA is still responding?! Surely it must be cached, but no, look at that timestamp 10:44:17.

Ok, that’s weird. But we’ve added ServiceB to Front Door over 12 minutes ago, surely if we just take ServiceA offline, the failover will kick in and divert traffic across to ServiceB. Lets try that.
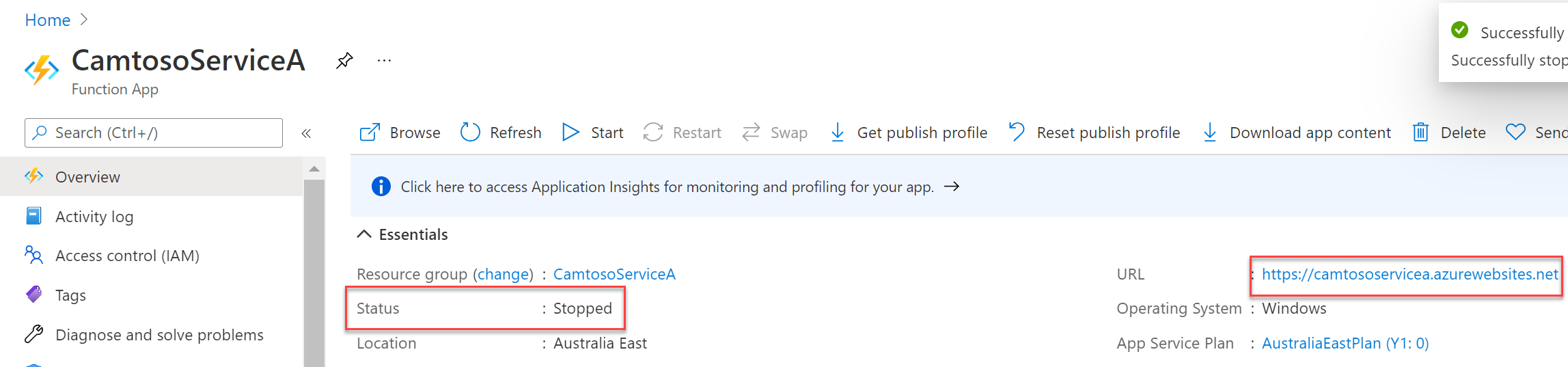
Step 4 – Decommission CamtosoServiceA
I’m going to stop Service A as you can see by the Status below.
Now lets return to the browser and try to hit the Front Door domain again and hope all that marketing material of Microsoft holds true that it’s doing constant latency and health monitoring of the backends and Front Door is going to do real-time failover….
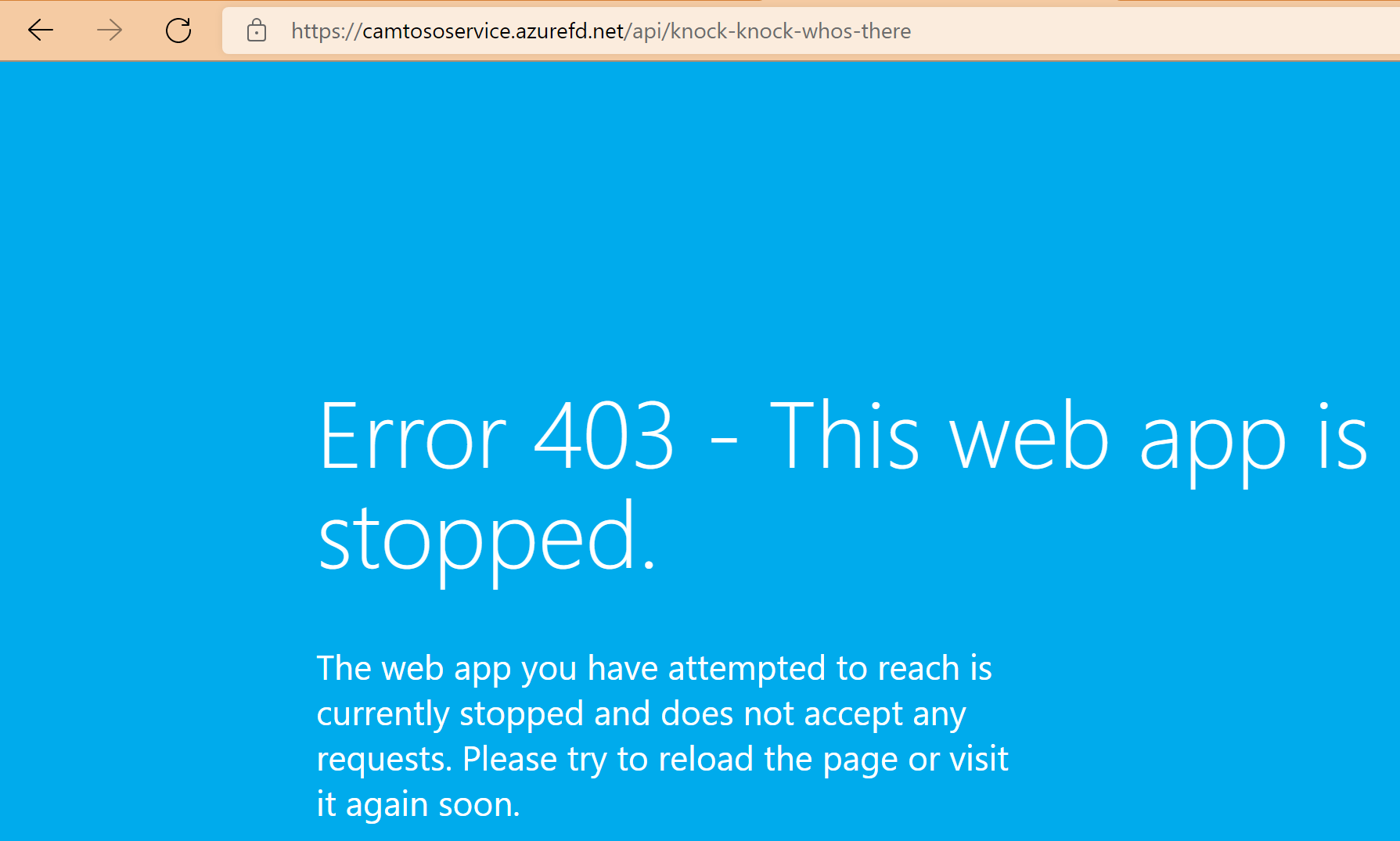
So here we are, it has been over 20 minutes since ServiceB was added to Front Door, and 5 minutes since ServiceA was removed from Front Door. Trying to hit the service via the Front Door domain is still routing through to ServiceA (which no longer exists) and fails to route to ServiceB, which we can still hit directly and is working fine.

And finally there is life
Fast forward another 15 minutes (now 35 minutes since adding ServiceB to Front Door) the requests are finally routed through to ServiceB and we get a successful response.

Further Experiments
Determined to find a faster way to get Front Door to acknowledge the new backend I tried the following two approaches.
Disable the Backend
It is possible in Front Door to Enable/Disable a backend. So I tested if the disabling ServiceA after adding ServiceB would be more immediate in achieving blue/green deployment. This made no difference. I was still getting routed through to ServiceA for a long time after I had disabled it in Front Door.
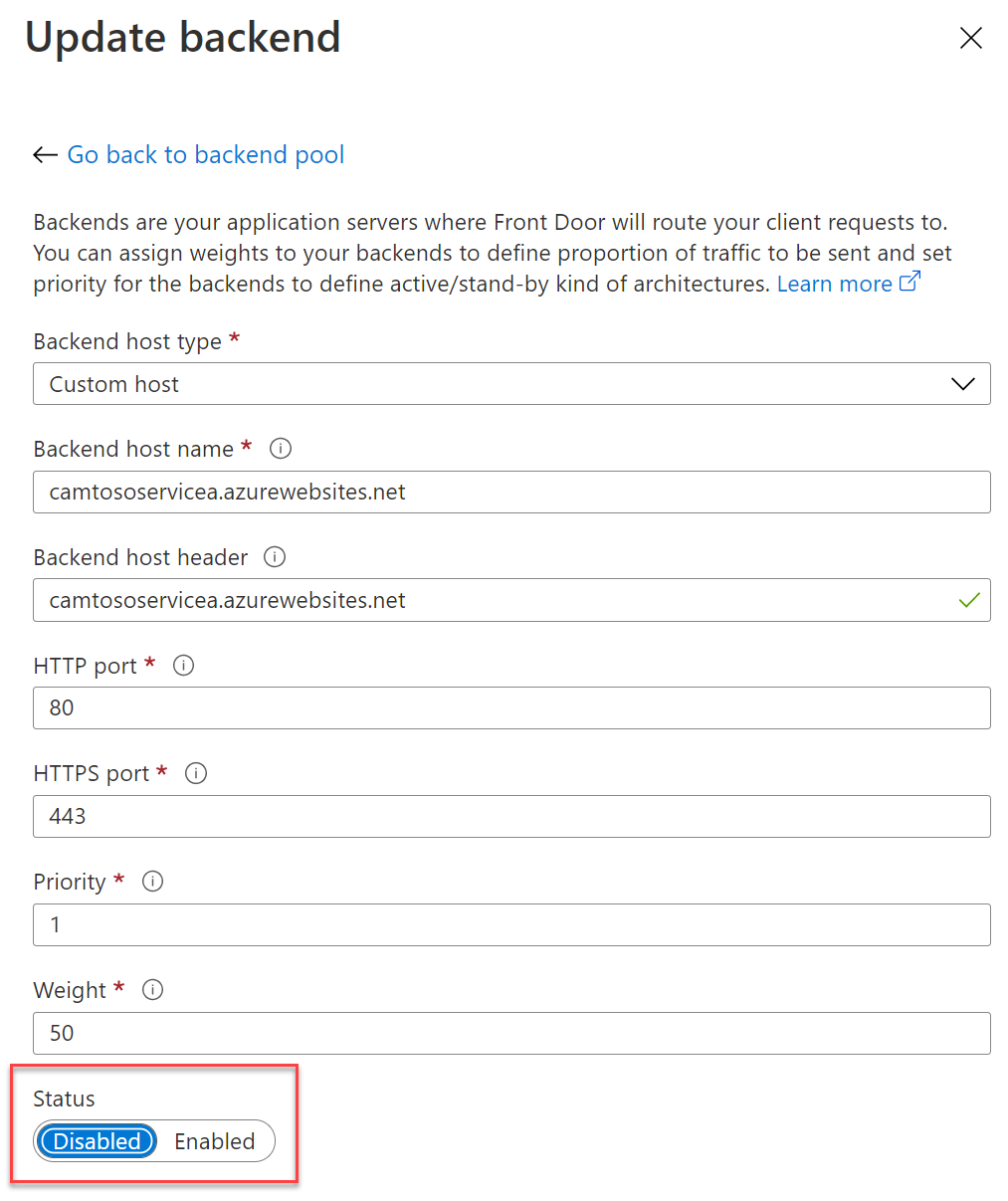
Change the Backend Weighting
It is also possible in Front Door to assign different weightings to each backend. I found this made no difference at either.
Conclusions
According to the official Microsoft docs, the delay/latency of adding/removing backends to the backend pools should be immediate.
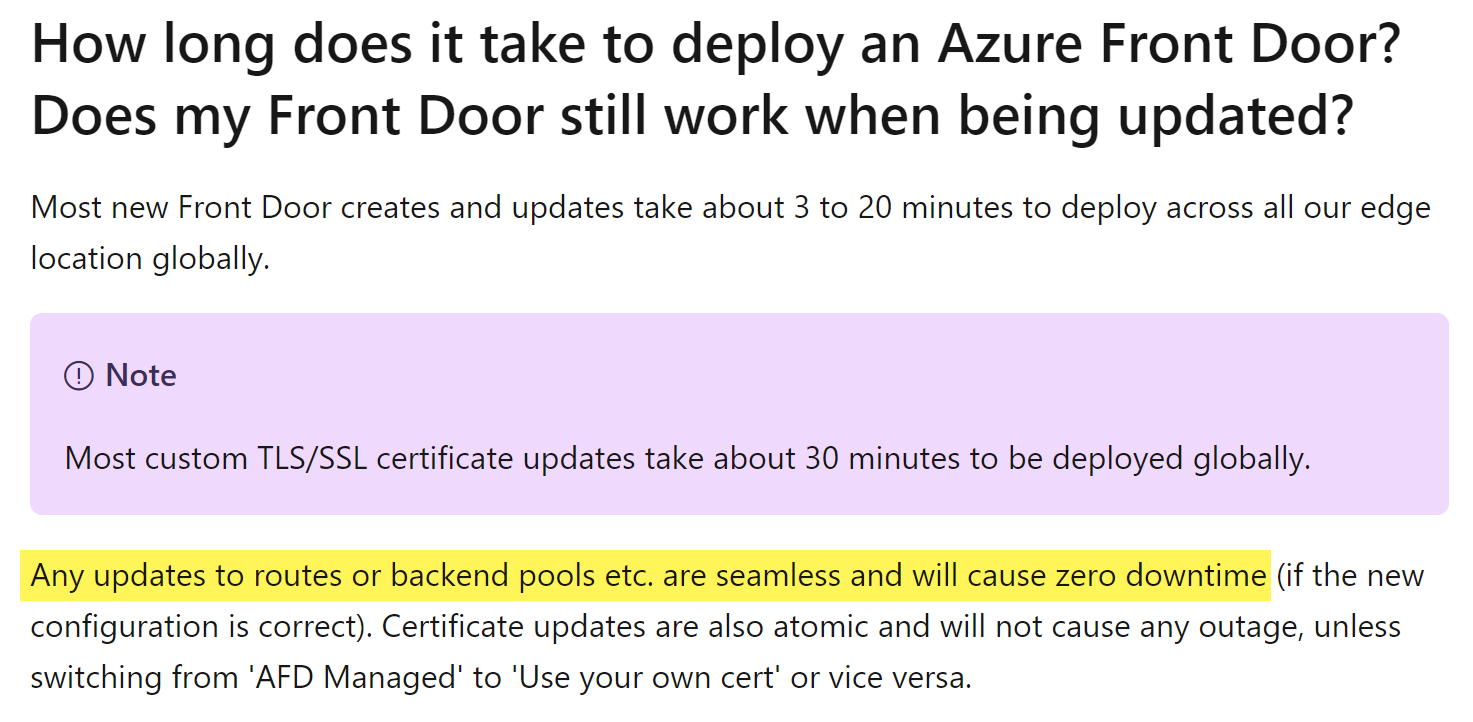
My takeaway is that the routing based on health probe monitoring only applies once the configuration has been setup (that is you have multiple backends and one becomes unavailable but you haven’t modified the Front Door configuration). It appears configuration changes made to Front Door such as adding/removing backends, changing weighting of backends, or marking a backend as disabled have a significant delay in the change taking affect (over 30 minutes).
With the lengthy delays Front Door takes to do this configuration change rollout, it is really hard to build a fully automated pipeline for a blue/green rollout that doesn’t involve a manual gate (between Step 3 and 4) for someone to check that Front Door is no longer routing requests to the service you want to decommission or to have some long running process continually testing Front Door and having a way for your service to respond so you know the latest version is the one responding, or more importantly that you don’t get routed to the old service anymore (which can get complicated if you do legitimately have multiple backends in production and weightings being applied).
References
Backends and backend pools in Azure Front Door | Microsoft Docs
Azure Front Door – backend health monitoring | Microsoft Docs

Have you tried disabling the “Session Affinity” option? It can be found within the Front Door Designer in any entry in the first left block “Frontends/domains” at the bottom.
LikeLike