I was recently testing the automatic scaling capabilities of Azure App Service plans. I had a static website and a Web API running off the same Azure App Service plan. It was a Production S1 Plan.

The static website was small (less than 10MB) and the Web API exposed a single method which did some file manipulation on files up to 25MB in size. This had the potential to drive memory usage up as the files would be held in memory while this took place. I wanted to be sure that under load my service wouldn’t run out of memory and die on me. Could Azure’s ability to auto-scale handle this scenario and spin up new instances of the App Service dynamically when the load got heavy? The upsides if this worked are obvious; I wouldn’t have to pay the fixed price of a more expensive plan that provided more memory 100% of the time, instead I’d just pay for the additional instance(s) that get dynamically spun up when I need them and therefore the extra cost during those periods would be warranted.
As an aside before I get started, it’s worth pointing out that the memory usage reporting works totally different on the Dev/Test Free plan than on Production plans, and I’d guess this has to do with the fact that the Free plan is a shared plan where it really doesn’t have it’s own dedicated resources.
What I noticed here is that if I ran my static website and Web API on the Dev/Test Free plan then my memory usage sat at 0% when idle. As soon as I change the plan to a production S1 then memory sat at around 55% when idle.
Enabling scale out is really simple, it’s just a matter of setting the trigger(s) for when you want to scale out (create additional instances) and I was impressed with a few of the other options that gave fine grained control over the sample period and cool-down periods to ensure scaling would happen in a sensible and measured way.
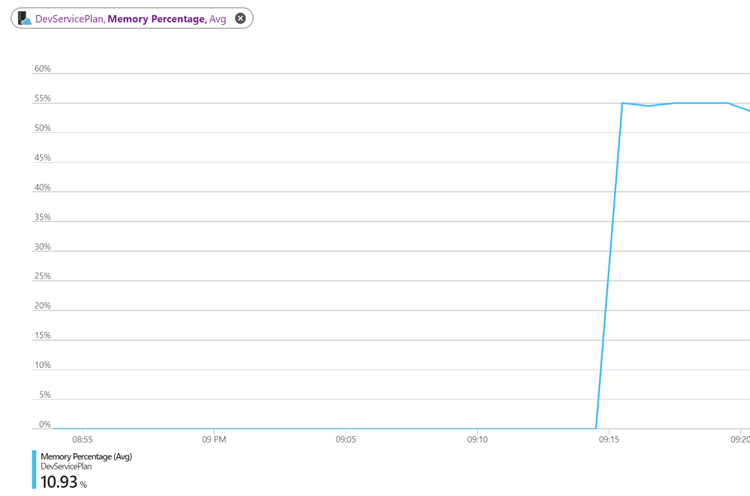
Before configuring my scale out rules, I first wanted to check my test rig and measure the load it would put on a single instance so I knew at what level to set my scaling thresholds. This is how the service behaved with just the one instance (no scaling)
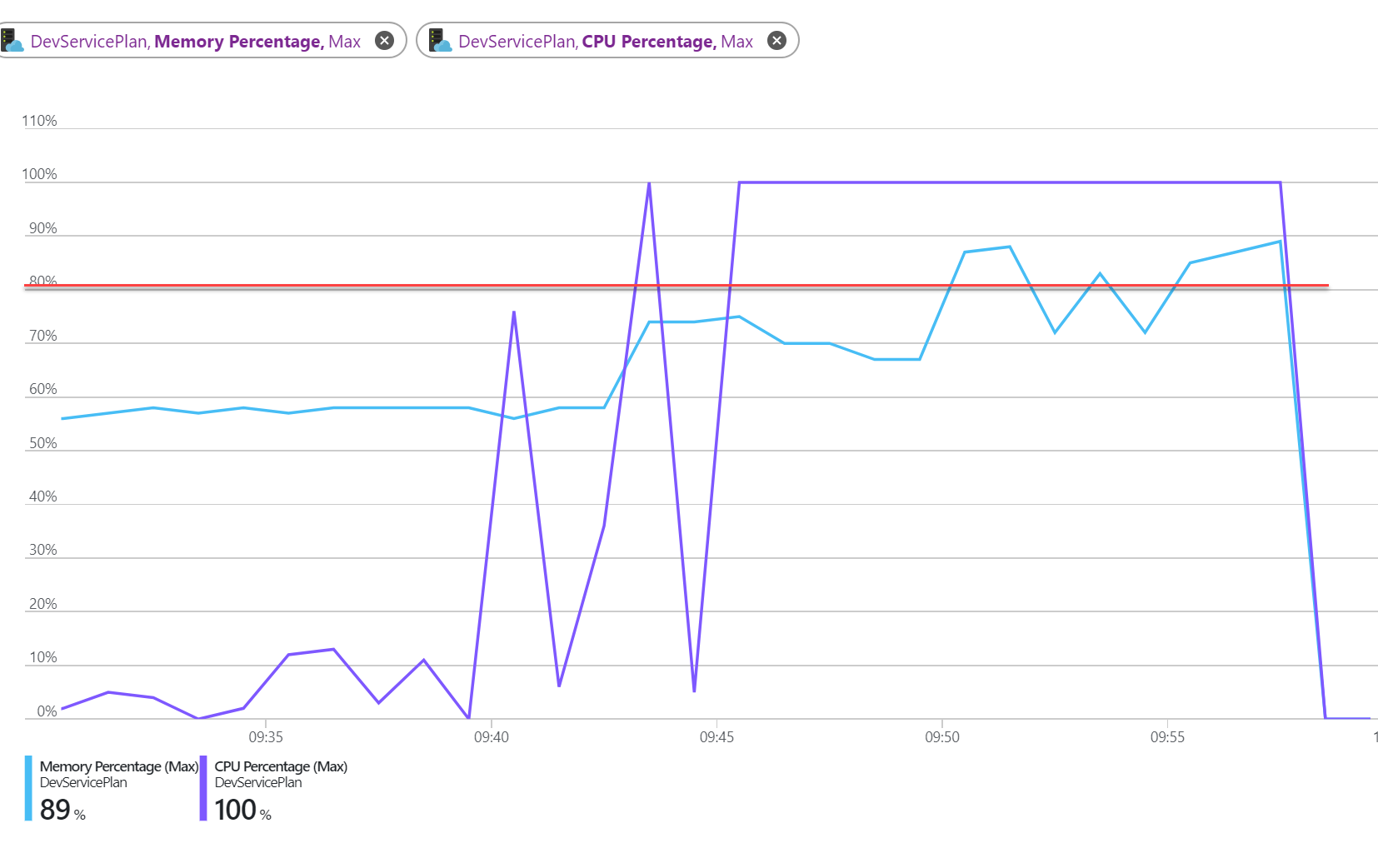
You can see that the test was going to consistently get both the CPU and Memory usage above 80%.
Next I went about configuring the scale out rules. Here I’ve set it to scale out if the average CPU Usage > 80% or the Memory Usage > 80%. I also set the maximum instances to 6.

I also liked the option to get notified and receive an email when scaling creates or removes an instance.
So did it work? Let’s see what happened when I started applying some load to both the static website and the Web API.
Before long I started getting emails notifying me that it was scaling up, each new instance resulted in an email like this

These graphs show what happened as more and more load was gradually applied. The red box is before scaling was enabled and the the green box shows how the system behaved as more load was applied and the number of instances grew from 1 to 6 instances. While the CPU and Memory dropped notice how the amount of Data Out and Data In during the green period was significantly higher? Not only was the CPU and Memory usage on average across the instances lower, but it was able to process a much higher volume of requests.
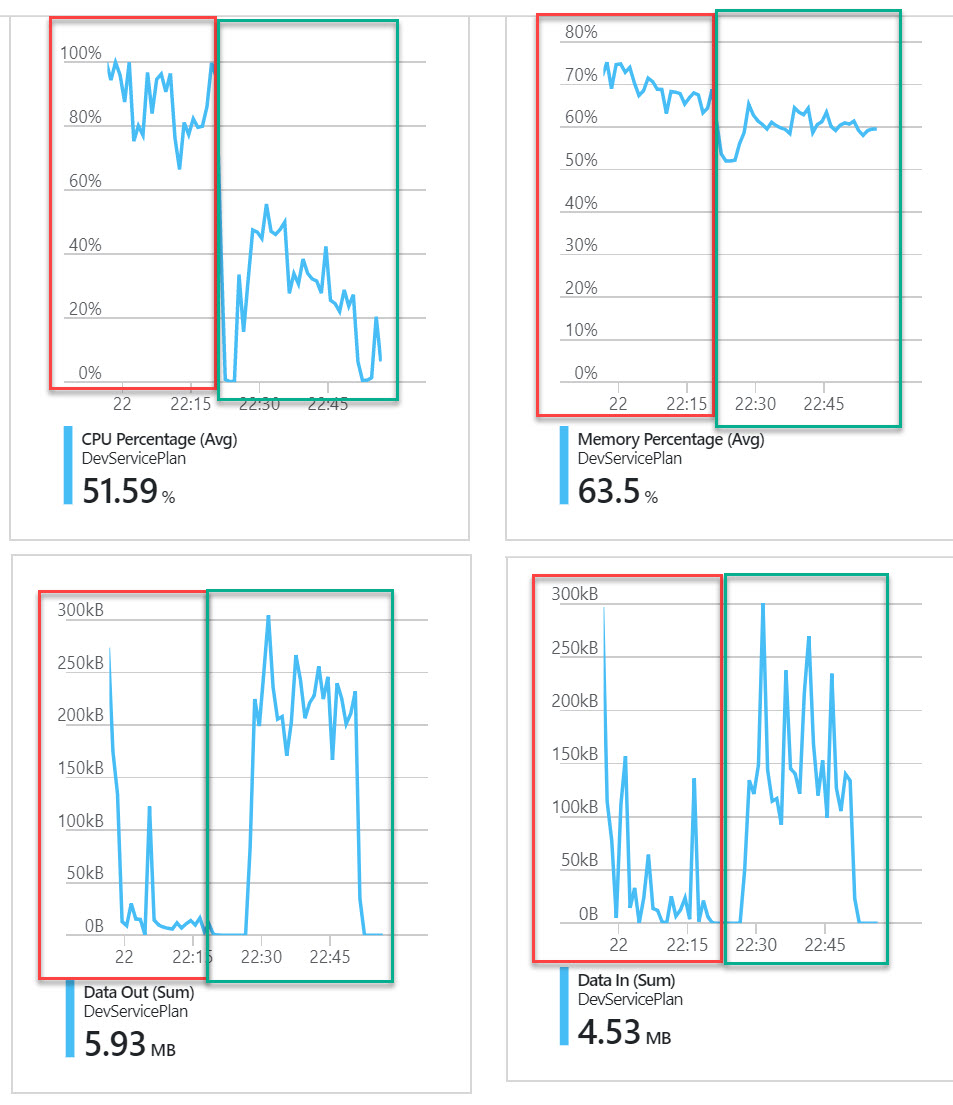
I have to say, I was pretty impressed when I first watched all this happen automatically in-front of my eyes. During testing I was also recording the response codes from every call I was making the the static website and Web API. Not a single request failed during the entire test.
But what happened when I stopped applying such a heavy load on the website and web API? Would it scale down just as gracefully? Read on for part two of this test to find out.

Good article on Azure App Service. More insights on Scale in part especially…. Good one.
LikeLiked by 1 person