This is the continuation of my experience with testing the auto-scaling capabilities of the Azure App Service. The first post dealt with scaling out as load increases, and this post deals with scaling back in when load decreases.
On the Scale Out blade of the App Service Plan you can see the current number of instances it has scaled to along with the Run History of scaling events (such as when each new instance was triggered and when it came online). Here we can see that under load my App Service Plan had scaled out to 6 instances, which was the maximum number of instance I’d configured for it to scale out to.
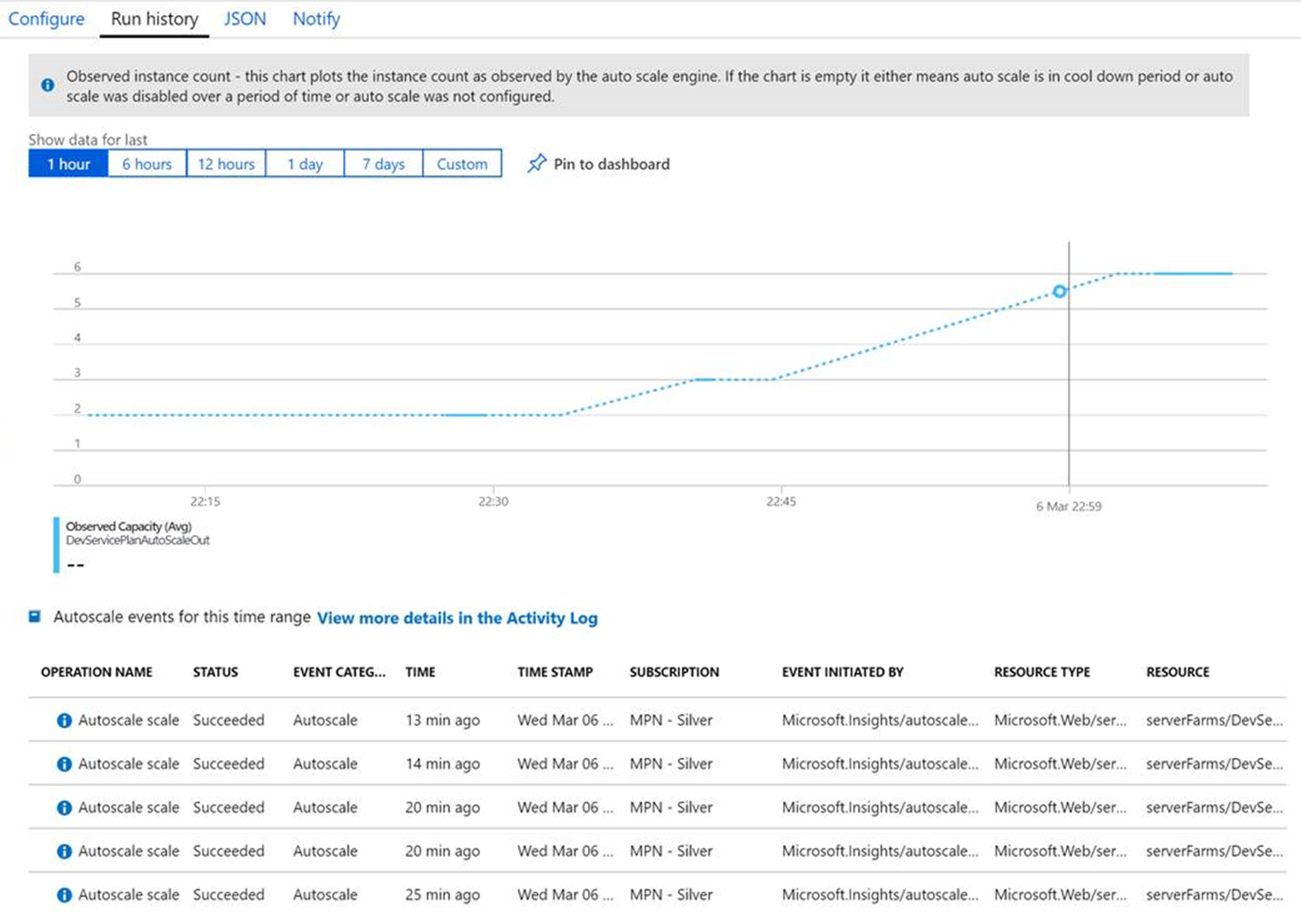
At this stage I removed the heavy load testing to watch it scale back down. In fact I cut all calls to the service so it was experiencing zero traffic. I was starting to get worried after 20 mins as I still had 6 instances and no sign of it attempting to scale back in. Then I realised I had to also setup scale in rules – it won’t do it by itself!
On the same page I configured the rules of when to scale out, I also needed to configure rules to trigger it to scale in again. I configured a simple rule that when the CPU dropped below 70% then it’s time to scale back in an instance. I set the cool down period to 2 minutes so I didn’t have to wait around forever to see it scale in.
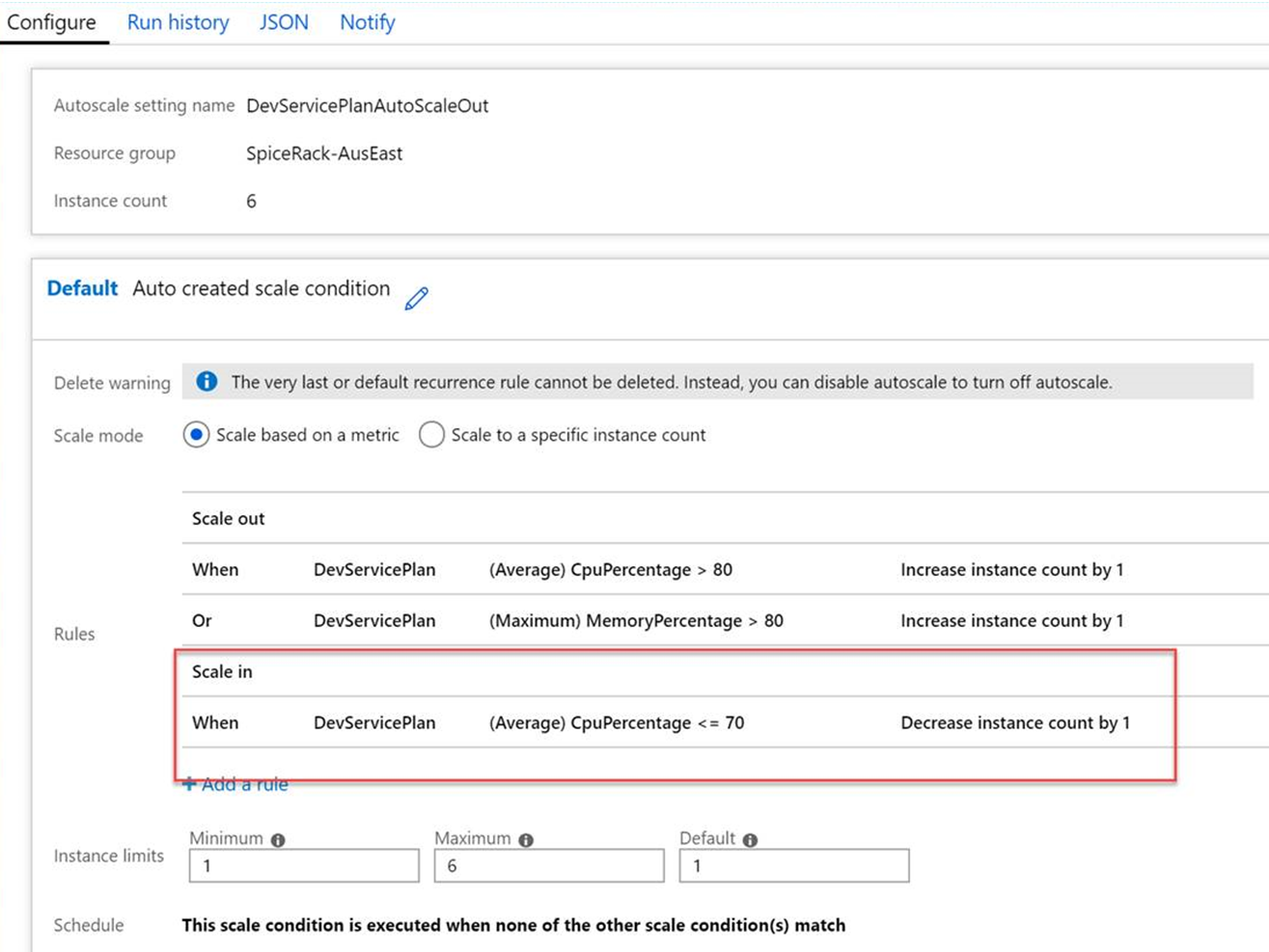
After saving those configuration changes, I expected to see the number of instances scale in and decrease by 1 every 2 minutes until it was back to a single instance.
Suddenly an email notification popped up, it had started happening!

I received the notifications and watched the Azure Portal over the next few minutes as it scales back from 6 to 5 to 4 to 3 instances. Then it stopped scaling in. I waiting over half an hour, scratching my head as to why it was failing to scale in. The CPU usage graph showed it was well under the scale in threshold of 70%, in fact it had peaked at 16% during that half hour of waiting. Why were these instances stuck running? I was paying for those instances and I didn’t need them.
On re-reading the Microsoft documentation on scaling best-practices, it became clear what was happening. You have to consider what Azure is trying to do when it’s scaling in. When Azure looks to scale in, it tries to predict the position it’s going to be in after the scale in operation to ensure it’s not placing itself in a position where it would trigger an immediate scale out operation again. So let’s look at how Azure was handling this scenario.
It had 3 instances running, from my first blog post of scaling up we had already established that each instance sat at 55% memory usage and nearly 0% CPU usage when it was idle. The trigger to scale down was when CPU usage was lower than 70%. The average CPU usage was under 15% so Azure had passed the trigger to scale in. But let’s look at what Azure thinks will happen to memory utilisation if it were to scale in. Each of the instances had 1.75GB memory allocated to it (based on the size of an S1 plan). So in Azure’s eyes my 3 instances each running at 55% memory usage required a total of 2.89GB (1.75GB*0.55*3). If we scaled in and were left with 2 instances then those 2 instances would have to be able to handle the total memory usage of 2.89GB (1.44GB each). Let’s do the maths on what the resulting memory usage on each of our instances would be (1.44/1.75*100) 82%. Remember the scale out rules I had set? they were set to scale out when memory usage was over 80%. Azure was refusing to scale in because it thought that would result in an immediate scale out operation again. What Azure was failing to take into account was that baseline memory that every new instance uses 55% memory (or 0.96GB) just doing nothing.
In reality, if Azure did scale in by one instance the remaining 2 instances would both continue to run at 55% memory usage and then scaling down to 1 instance would again result in the last single instance running at 55% memory usage.
Azure auto scale in isn’t the perfect predictor of what’s going to happen and you will need to pay careful attention to the metrics you are using to scale on. My advice would be to test your scaling configuration by load testing as I’ve done here so that you can have confidence that you’ve actually seen what happens under load. As this little test has proven sometimes the behaviour isn’t always obvious and what you’d expect, and a mistake here could lead to some nasty bill shock.
If you are stuck with scenarios when you can’t auto scale in, or you are concerned with scale in not working then here’s a few options to consider:
- Configure a scheduled scale-in rule to forcible bring the instance count back to 1 at a time of day when you expect least traffic
- Configure a periodic alert to notify you if the number of instance is over a certain amount, you could then manually reduce the count back to 1.

Thanks, this helped me understand why my service plan isn’t scaling in !
LikeLiked by 1 person